CloudMatrix384 with Ascend 910/920: How DeepSeek Cuts AI Costs by 90% vs Nvidia H100
Published on 2025-08-02
Last updated: 2025-09-23
TL;DR
- Huawei CloudMatrix384 (Ascend 910C) can deliver very competitive LLM inference economics for DeepSeek models compared to Nvidia H100, according to reported internal benchmarks.
- Key metrics reported: up to 6,688 tokens/s per NPU prefill and 1,943 tokens/s per NPU decode, with architecture-level optimizations for MoE and MLA.
- The upcoming Ascend 920C targets higher FP16 throughput and HBM3 bandwidth; power efficiency remains a trade-off vs Nvidia GB200.
- For buyers: Evaluate availability, toolchain maturity (CANN/CUNN), and ecosystem support alongside raw throughput and price.
Why DeepSeek is efficient and cost-competitive
DeepSeek has reshaped open LLM economics by releasing high-performance models with permissive licensing and aggressive optimizations. The team reports deploying training on Nvidia hardware while moving significant inference to Huawei Ascend for cost efficiency. This article summarizes publicly reported performance data and architecture details to help practitioners understand trade‑offs.
Note: All prices and throughput figures below are best-effort summaries of publicly reported numbers and may vary by provider, region, and workload. Always validate against your target deployment.
Key takeaways
- CloudMatrix384 focuses on peer-to-peer serving and disaggregated prefill/decode/caching to maximize MoE utilization.
- CANN/CUNN provide a CUDA-adjacent toolchain; migration effort depends on kernels and framework use.
- Reported prefill/decode throughput per NPU is competitive for R1/V3 serving; total TCO hinges on availability and ops costs.
- Nvidia retains an advantage in energy efficiency on the latest GB200 systems; Huawei emphasizes scale and cost per token.
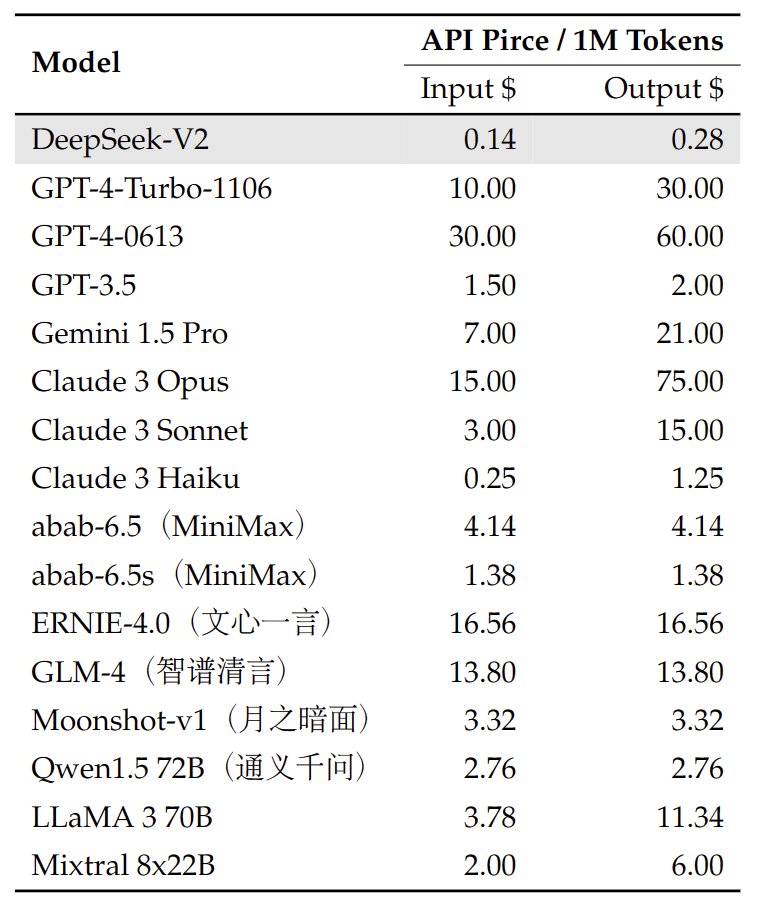
At‑a‑glance pricing context (reported)
| Item | Reported indicative price | Notes |
|---|---|---|
| DeepSeek V3 input (Ascend 910C) | ~1 CNY / 1M tokens | Promotional pricing; provider dependent |
| DeepSeek R1 input (Ascend 910C) | ~4 CNY / 1M tokens | Promotional pricing; provider dependent |
| Nvidia H100 cloud inference | Higher typical cost | Strong efficiency; depends on vendor/region |
For current cloud GPU rates, see: GPU Cloud Pricing · GPU Providers · Compute Capability.
DeepSeek Models and Their Deployment Strategy
The DeepSeek model family (V3, R1) represents a breakthrough in open-source LLM development, with deployment strategies optimized for both Nvidia and Huawei hardware ecosystems:
Model Architecture Characteristics:
DeepSeek-V3 Technical Specifications:
- 671B total parameters with 37B activated parameters per token
- Mixture-of-Experts (MoE) architecture with 257 experts and Top-8 routing
- Multi-Head Latent Attention (MLA) reducing KV cache memory requirements
- Context Length: 128K tokens with efficient attention mechanisms
- Training Data: 14.8T tokens with diverse multilingual and code datasets
DeepSeek-R1 Enhanced Capabilities:
- Advanced reasoning model with reinforcement learning from human feedback (RLHF)
- Chain-of-thought reasoning optimized for complex problem-solving
- Distillation support enabling deployment of smaller, efficient variants
- MIT License providing unrestricted commercial usage rights
Nvidia H800 Deployment Strategy:
Training Infrastructure:
- 2,048 Nvidia H800 GPUs used for DeepSeek-R1 training
- Advanced parallelism strategies: Combination of DP, TP, EP, and PP (Pipeline Parallelism)
- Custom communication libraries: DeepEP for efficient expert parallelism
- Optimized kernels: DeepGEMM FP8 library achieving 1350+ TFLOPS on Hopper architecture
Performance Optimization:
- FlashMLA kernels: Efficient MLA decoding optimized for variable-length sequences
- Memory management: Paged KV cache with 64-token blocks for optimal memory utilization
- Communication overlap: DualPipe bidirectional pipeline parallelism for training efficiency
- Load balancing: EPLB (Expert-Parallel Load Balancer) for optimal expert utilization
Hybrid Deployment Model:
- Training Phase: Utilizes Nvidia H800 clusters for model development and refinement
- Inference Phase: Migrates to Huawei 910C for cost-effective deployment
- Model Optimization: Leverages both ecosystems' strengths for optimal performance-cost balance
Huawei Ascend 910C: Driving DeepSeek's Cost-Effective AI Innovation

The Huawei Ascend 910C is a powerful AI accelerator chip from Huawei's HiSilicon, designed to rival Nvidia's H100 GPU in the AI hardware market. Built on SMIC's 7nm N+2 process, it features 53 billion transistors and excels in AI inference, delivering 320 TFLOPS of FP16 performance—approximately 60–70% of Nvidia's H100 inference capabilities. Integrated with Huawei's CANN framework and CloudMatrix 384, it supports DeepSeek's R1 and V3 models, enabling cost-effective AI deployment at 1 yuan per million tokens. This partnership aligns with China's goal of AI self-sufficiency amid U.S. export restrictions.
Detailed Specifications:
- Process Technology: SMIC 7nm N+2, a domestic alternative to TSMC's advanced nodes.
- Transistor Count: ~53 billion, reflecting high computational density.
- Performance: 320 TFLOPS FP16, with FP8 and BF16 precision for efficient inference.
- Chiplet Design: Integrates two Ascend 910B logic dies for enhanced performance.
- Memory: Likely uses HBM (High Bandwidth Memory), though details are limited due to sanctions.
- Software Ecosystem: Huawei's CANN framework supports PyTorch, enabling seamless CUDA-to-CUNN transitions.
- Power Efficiency: Offers significant cost savings, with DeepSeek's inference costs far lower than Nvidia-based solutions.
- Production Scale: Huawei targets 1.4 million 910C chips by December 2025, with SMIC producing ~400,000 units monthly.
Huawei's Strategic Partnership with DeepSeek
AI Inference Excellence
The 910C powers inference for DeepSeek's R1 and V3 models, leveraging FP8 and BF16 precision for efficiency. DeepSeek achieves pricing as low as 1 yuan per million input tokens for V3 and 4 yuan for R1, compared to $7 on Nvidia-based clouds.
Revolutionary Cost Efficiency
The 910C's performance-to-cost ratio undercuts Nvidia, making AI accessible to small and medium enterprises. DeepSeek's open-source models, like R1 (MIT License), benefit from 910C's affordability.
Cloud Integration and Ecosystem
Runs on Huawei Cloud's CloudMatrix 384, which DeepSeek claims outperforms Nvidia processors for R1 inference. Partnerships with providers like SiliconFlow enhance accessibility for global developers.
Reducing Nvidia Dependency
The 910C's CANN framework and CUNN kernels provide a CUDA alternative, reducing reliance on Nvidia GPUs. Over 20,000 developers engaged with DeepSeek's platform shortly after its launch, signaling ecosystem growth.
Geopolitical Impact and Market Disruption
Supports China's AI self-sufficiency by mitigating U.S. sanctions on advanced chips. DeepSeek's use of 910C for inference challenges Nvidia's market dominance, contributing to a 3.12% drop in Nvidia's stock on January 25, 2025.
Huawei Ascend 920C: The Next-Generation AI Powerhouse
Revolutionary Performance Specifications
The upcoming Huawei Ascend 920C represents a quantum leap in AI processing capabilities, built on SMIC's 6nm process and expected to enter mass production in H2 2025:
Core Performance Metrics:
- Over 900 TFLOPS of FP16 compute performance per chip
- HBM3 memory delivering approximately 4,000 GB/s bandwidth (vs 3,200 GB/s on 910C's HBM2E)
- CloudMatrix 384 cluster achieves 300 PFLOPS vs 180 PFLOPS on Nvidia's GB200 NVL72
- 30-40% efficiency gains over 910C in training workloads
Benchmark Performance vs Nvidia GB200
Internal Huawei benchmarks reveal impressive performance comparisons:
Cluster-Level Performance:
- CloudMatrix 384 (Huawei's AI Super Node) outperforms Nvidia's GB200 NVL72 in internal testing
- 300 PFLOPS aggregate performance from Huawei's system
- Optimized specifically for both training and inference workloads
- Chiplet-based architecture refined for Transformer and MoE models
Power Efficiency Challenges:
- 559 kW power consumption for 920C vs 132 kW for GB200
- Represents the primary area where Nvidia maintains advantage
- Huawei actively developing efficiency improvements in 920 series
Huawei CloudMatrix384: Production-Grade AI Infrastructure
Revolutionary Architecture Overview
The CloudMatrix384 represents Huawei's production-grade realization of next-generation AI datacenter architecture, addressing critical challenges in LLM infrastructure through innovative hardware-software co-design:
Core Infrastructure:
- 384 Ascend 910 NPUs integrated with 192 Kunpeng CPUs in unified supernode
- Unified Bus (UB) Network enabling direct all-to-all communication bypassing hierarchical limitations
- Three Network Planes: UB (intra-supernode), RDMA (scale-out), VPC (datacenter integration)
- Peer-to-peer architecture allowing dynamic resource pooling and independent scaling
Technical Advantages for LLM Serving:
- Communication-intensive operations like large-scale MoE expert parallelism optimized
- Distributed KV cache access with high-bandwidth uniform access via UB network
- Memory-class storage through disaggregated memory pooling
- Fine-grained resource disaggregation for flexible workload management
CloudMatrix-Infer: Breakthrough Performance Results
The CloudMatrix-Infer solution establishes best practices for deploying large-scale MoE models like DeepSeek-R1 on CloudMatrix384, achieving industry-leading efficiency:
Performance Benchmarks:
- Prefill throughput: 6,688 tokens/s per NPU (4.45 tokens/s/TFLOPS efficiency)
- Decode throughput: 1,943 tokens/s per NPU at <50ms TPOT (1.29 tokens/s/TFLOPS efficiency)
- Latency optimization: 538 tokens/s per NPU sustained under strict <15ms TPOT constraint
- Surpasses published results for SGLang on Nvidia H100 and DeepSeek on Nvidia H800
Key Technical Innovations:
Peer-to-Peer Serving Architecture (PDC Disaggregation):
- Disaggregates Prefill, Decode, and Caching into independently scalable resource pools
- Unlike KV cache-centric architectures, enables high-bandwidth uniform access to cached data
- Reduces data locality constraints and simplifies task scheduling
Large-Scale Expert Parallelism:
- Supports EP320 (Expert Parallelism degree 320) enabling each NPU die to host exactly one expert
- Fused Communication Operators: FusedDispatch, FusedCombine with AIV-Direct NPU-to-NPU communication
- Optimized MLA computation with DeepSeek's Multi-Head Latent Attention architecture
Advanced Optimization Features:
- INT8 quantization maintaining accuracy comparable to official DeepSeek-R1 API across 16 benchmarks
- Microbatch-based pipelining for computation-communication overlap
- Multiple-Token Prediction (MTP) support for speculative decoding
- Context and Model Caching through distributed memory pooling
Software Ecosystem Integration
CANN Framework Enhancement:
- Driver and runtime optimized for Ascend 910 NPUs
- Graph engine with framework integration for PyTorch, TensorFlow, ONNX, MindSpore
- Cloud deployment infrastructure: MatrixResource, MatrixLink, MatrixCompute, MatrixContainer, ModelArts
DeepSeek Model Synergy:
- MoE communication optimization leveraging CloudMatrix384's architecture
- Memory capacity sufficient for large-scale model deployment
- Context cache reuse through UB-driven distributed caching
- Quantization support with mixed-precision strategies
SGLang Integration with Huawei Ascend
The integration of SGLang (Structured Generation Language) with Huawei Ascend represents a significant advancement in LLM serving efficiency, demonstrating competitive performance against established Nvidia-based solutions:
SGLang Framework Advantages:
- Structured Generation: Advanced prompt engineering and response structuring capabilities
- Efficient Serving: Optimized inference engine for production-scale LLM deployment
- Flexible APIs: Comprehensive REST and gRPC interfaces for diverse application integration
- Batch Processing: Sophisticated batching strategies for optimal throughput
Ascend-Optimized Implementation:
Performance Benchmarks:
- CloudMatrix-Infer achieving 6,688 tokens/s per NPU prefill throughput
- Efficiency metrics: 4.45 tokens/s/TFLOPS prefill efficiency exceeding SGLang on Nvidia H100
- Decode performance: 1,943 tokens/s per NPU at <50ms TPOT latency
- Competitive latency: 538 tokens/s per NPU sustained under strict <15ms TPOT constraints
Technical Optimizations:
Memory Management:
- NZ-formatted KV Cache: Optimized cache storage format specifically for Ascend NPU architecture
- Distributed Caching: UB-driven memory pooling enabling uniform cache access across supernodes
- Context Caching: Intelligent reuse of computation for repeated prompt patterns
- Model Caching: Efficient model weight distribution and caching strategies
Communication Optimization:
- Low-interference Transferring: RDMA-plane based KV cache transfer minimizing computation impact
- Asynchronous Prefill Scheduling: Non-blocking prefill operations for improved throughput
- Load-balanced Connection Mapping: Optimal prefill-decode connection strategies
- Fused Operators: AIV-Direct communication bypassing traditional network stacks
Deployment Features:
- Elastic Memory Service (EMS): Huawei Cloud service providing distributed caching capabilities
- Automatic Scaling: Dynamic resource allocation based on workload demands
- Multi-Model Support: Simultaneous serving of multiple model variants with shared infrastructure
- Production Monitoring: Comprehensive metrics and performance monitoring for operational deployment
Comparison with Nvidia Ecosystem:
- Hardware Efficiency: Ascend 910 achieving competitive performance per TFLOP
- Cost Effectiveness: Significant operational cost reduction compared to H100-based deployments
- Ecosystem Maturity: While CUDA ecosystem remains more mature, CANN demonstrates production readiness
- Future Trajectory: Rapid improvement in performance and feature parity with ongoing development
Detailed Technical Deep-Dive: CloudMatrix384 Components
CloudMatrix384 Architecture Details
The CloudMatrix384 system represents a paradigm shift from conventional hierarchical AI cluster designs to a fully peer-to-peer architecture that enables unprecedented scalability and efficiency:
System Configuration:
- Unified Supernode: 384 Ascend 910 NPUs and 192 Kunpeng CPUs integrated into single logical unit
- Memory-Class Storage: Direct access to distributed memory pools across all nodes
- Resource Pooling: Compute, memory, and network resources dynamically allocated based on workload demands
- Uniform Access Model: All resources accessible with consistent latency and bandwidth characteristics
Network Architecture Innovation:
- UB (Unified Bus) Network: Ultra-high-bandwidth, low-latency interconnect enabling direct all-to-all communication
- RDMA Plane: Scale-out communication for multi-supernode deployments
- VPC Plane: Integration with broader datacenter infrastructure and external services
Key Architectural Benefits:
- Eliminates hierarchical bottlenecks common in traditional cluster designs
- Enables efficient large-scale expert parallelism with direct NPU-to-NPU communication
- Supports disaggregated workloads where prefill, decode, and caching operate independently
- Provides uniform memory access across the entire supernode for optimal cache utilization
Ascend 910 Chip Technical Specifications
The Ascend 910 NPU serves as the fundamental compute unit within CloudMatrix384, specifically designed for AI workloads with architecture optimized for transformer and MoE models:
Core Architecture:
- AI Core Design: Specialized tensor processing units optimized for neural network operations
- Memory Subsystem: Integrated with high-bandwidth memory (HBM2E in current generation, HBM3 in 920C)
- Communication Interfaces: Native support for UB network protocols and RDMA communication
- Precision Support: FP32, FP16, BF16, INT8 with specialized quantization acceleration
Performance Characteristics:
- Compute Throughput: 320 TFLOPS FP16 performance for 910C variant
- Memory Bandwidth: 3,200 GB/s with HBM2E (910C), upgrading to 4,000 GB/s with HBM3 (920C)
- Inter-chip Communication: Direct NPU-to-NPU communication via AIV-Direct bypassing traditional SDMA protocols
- Energy Efficiency: Optimized for sustained workloads with advanced power management
Specialized AI Features:
- MLA Acceleration: Hardware optimizations for DeepSeek's Multi-Head Latent Attention architecture
- Quantization Support: Native INT8 operations with adaptive scale search and outlier suppression
- Communication Offload: Fused communication operators for expert parallelism and all-to-all operations
- Memory Management: NZ-formatted KV cache for optimized attention operations
Ascend 910 Node Architecture
Each Ascend 910 Node within CloudMatrix384 represents a carefully balanced compute unit designed to maximize both individual performance and cluster-level efficiency:
Node Composition:
- Dual Ascend 910 NPUs: Two NPU dies per node for increased local compute density
- Kunpeng CPU Integration: ARM-based CPU providing control plane and data preprocessing capabilities
- Local Memory Pool: Node-level DRAM complementing NPU HBM for extended memory capacity
- Network Interfaces: Multiple high-speed connections to UB network fabric
Interconnect Design:
- Intra-Node Communication: Direct NPU-to-NPU links for local data exchange
- UB Network Connections: High-bandwidth connections enabling seamless inter-node communication
- RDMA Capabilities: Support for scale-out operations beyond single supernode
- Unified Memory Access: Transparent access to remote memory pools across entire supernode
Workload Distribution:
- Independent Task Execution: Each NPU can operate on different tasks simultaneously
- Coordinated Operations: Synchronized execution for large-scale parallelism strategies
- Dynamic Load Balancing: Runtime allocation based on workload characteristics and resource availability
- Fault Tolerance: Graceful degradation and workload redistribution in case of node failures
Performance Optimization:
- Cache Hierarchy: Multi-level caching optimized for AI workload access patterns
- Memory Controllers: Advanced memory management for optimal bandwidth utilization
- Thermal Management: Sophisticated cooling integration for sustained high-performance operation
CANN for Ascend NPUs: Complete Software Stack
The Compute Architecture for Neural Networks (CANN) provides a comprehensive software ecosystem specifically designed for Ascend NPUs, offering both performance optimization and developer accessibility:
Core Framework Components:
Driver and Runtime Layer:
- Device Drivers: Low-level hardware control and resource management for Ascend NPUs
- Runtime APIs: High-performance APIs for memory management, kernel execution, and device coordination
- Resource Allocation: Dynamic resource management across multiple NPUs and memory pools
- Hardware Abstraction: Unified interface masking hardware complexity from higher-level frameworks
Graph Engine and Optimization:
- Computational Graph: Advanced graph representation and optimization for neural network models
- Operator Fusion: Automatic fusion of operations to reduce memory bandwidth and improve performance
- Memory Optimization: Intelligent memory layout and access pattern optimization
- Parallelism Support: Native support for tensor parallelism (TP), data parallelism (DP), and expert parallelism (EP)
Framework Integration:
- PyTorch Support: Native PyTorch integration with CUNN (CUDA alternative) enabling seamless migration
- TensorFlow Compatibility: Full TensorFlow ecosystem support with optimized operations
- ONNX Runtime: Standard ONNX model deployment with hardware-specific optimizations
- MindSpore Integration: Huawei's native framework with deep CANN integration
Performance Acceleration Features:
Specialized Operators:
- MLAProlog: Fused pre-attention operator optimized for DeepSeek's MLA architecture
- Fused Attention (FA): FlashAttention implementation with data shaping optimizations
- Communication Primitives: FusedDispatch, FusedCombine for expert parallelism operations
- Quantization Kernels: Hardware-accelerated INT8 operations with accuracy preservation
Advanced Optimization Techniques:
- MTP-Aware Tiling: Dynamic tiling strategy optimized for Multi-Token Prediction workloads
- BSND Layout: Optimized memory layout for attention operations under MTP scenarios
- Hybrid Parallelism: SP-TP-SP strategy implementation for efficient prefill operations
- Microbatch Processing: Pipeline optimization for overlapping computation and communication
Cloud Deployment Infrastructure:
- MatrixResource: Resource management and allocation across CloudMatrix clusters
- MatrixLink: Network configuration and management for UB and RDMA planes
- MatrixCompute: Workload scheduling and execution management
- MatrixContainer: Containerized deployment support for cloud-native applications
- ModelArts: End-to-end model development, training, and deployment platform
DeepSeek's Software Innovation: The #OpenSourceWeek
It's not hardware alone, but a combination of:
- Money - Significant investment in infrastructure and development
- Minds - World-class engineering talent and research capabilities
- Software - After the release of DeepSeek-R1, they released the #OpenSourceWeek by introducing groundbreaking papers and code for their work:
Day 1 - FlashMLA
Honored to share FlashMLA - our efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences and now in production.
✅ BF16 support ✅ Paged KV cache (block size 64) ⚡ 3000 GB/s memory-bound & 580 TFLOPS compute-bound on H800
Day 2 - DeepEP
Excited to introduce DeepEP - the first open-source EP communication library for MoE model training and inference.
- Efficient and optimized all-to-all communication
- Both intranode and internode support with NVLink and RDMA
- High-throughput kernels for training and inference prefilling
- Low-latency kernels for inference decoding
- Native FP8 dispatch support
- Flexible GPU resource control for computation-communication overlapping
Day 3 - DeepGEMM
Introducing DeepGEMM - an FP8 GEMM library that supports both dense and MoE GEMMs, powering V3/R1 training and inference.
- Up to 1350+ FP8 TFLOPS on Hopper GPUs
- No heavy dependency, as clean as a tutorial
- Fully Just-In-Time compiled
- Core logic at ~300 lines - yet outperforms expert-tuned kernels across most matrix sizes
- Supports dense layout and two MoE layouts
Day 4 - Optimized Parallelism Strategies
- DualPipe - a bidirectional pipeline parallelism algorithm for computation-communication overlap in V3/R1 training.
- EPLB - an expert-parallel load balancer for V3/R1.
- Analyze computation-communication overlap in V3/R1.
Day 5 - 3FS, Thruster for All DeepSeek Data Access
Fire-Flyer File System (3FS) - a parallel file system that utilizes the full bandwidth of modern SSDs and RDMA networks.
⚡ 6.6 TiB/s aggregate read throughput in a 180-node cluster ⚡ 3.66 TiB/min throughput on GraySort benchmark in a 25-node cluster ⚡ 40+ GiB/s peak throughput per client node for KVCache lookup 🧬 Disaggregated architecture with strong consistency semantics ✅ Training data preprocessing, dataset loading, checkpoint saving/reloading, embedding vector search & KVCache lookups for inference in V3/R1
⛲ Smallpond - data processing framework on 3FS
Day 6 - DeepSeek-V3/R1 Inference System Overview
Optimized throughput and latency via:
- Cross-node EP-powered batch scaling
- Computation-communication overlap
- Load balancing
Statistics of DeepSeek's Online Service:
- 73.7k/14.8k input/output tokens per second per H800 node
- Cost profit margin 545%
We hope this week's insights offer value to the community and contribute to our shared AGI goals.
Market Response and Industry Expert Insights
Expert Analysis: The Strategic Partnership Impact
According to AI industry expert Yuchen Jin, the DeepSeek-Huawei partnership represents more than just cost optimization—it's reshaping the global AI hardware landscape. Key insights include:
Performance Benchmarks:
- Huawei 910C achieves 60% of H100's performance in real-world inference scenarios
- With optimized CUNN kernels and hand-written optimizations, performance can exceed initial benchmarks
- DeepSeek V3 supports inference on Huawei Ascend chips from Day 1 of release
Strategic Advantages:
- Cost Revolution: ByteDance's Doubao-1.5-Pro rivals GPT-4o at 1/50th the cost using similar optimization strategies
- Export Control Resilience: Tightening export controls only accelerates China's independent GPU development
- CUDA Alternative: Huawei maintains its own PyTorch repository, enabling one-line imports to port CUDA to CUNN
The Golden Era for Chinese AI Chips
The partnership signals the beginning of what experts call the "golden era" for Chinese semiconductor innovation:
Technical Breakthroughs:
- Transformer Architecture Convergence: As AI models standardize on Transformer architectures, the importance of CUDA diminishes
- Custom Kernel Optimization: Engineers can handwrite CUNN kernels for highly optimized performance
- Reduced Nvidia Dependency: Strategic choice driven by uncertainty around future GPU export restrictions
Market Validation:
- Over 20,000 developers engaged with DeepSeek's platform shortly after launch
- DeepSeek R1 topped App Store charts in 51 countries
- Cost profit margin of 545% demonstrates sustainable business model
Current Limitations and Challenges
Training Reliability: The 910C is less suited for sustained training compared to Nvidia GPUs, with DeepSeek using 2,048 Nvidia H800 GPUs for R1 training. Sanctions Impact: Limited access to advanced HBM and process nodes hampers scalability. Ecosystem Maturity: CANN lags behind Nvidia's CUDA, requiring further development for broader adoption.
Future Outlook for the Partnership
Huawei's Ascend 910D and 920C chips aim to close the training gap with Nvidia's Blackwell B200. DeepSeek's cost-effective, open-source models and 910C compatibility position it as a global AI leader, with R1 topping App Store charts in 51 countries. The partnership signals a shift toward diversified AI hardware, reducing Nvidia's dominance as Transformer architectures lessen CUDA dependency.
Manufacturing and Production Challenges
Yield Rates and Production Capacity
The path to mass production reveals both challenges and rapid improvements in Chinese semiconductor manufacturing:
910C Production Status:
- February 2025: Financial Times reported ~40% yield rate with 100,000 unit capacity
- March 2025: CSIS challenged FT figures, claiming yields remained around 20%
- April 2025: Industry sources indicate yields sufficient for mass production justification
920C Production Timeline:
- Mass production targeted for second half of 2025
- Built on SMIC's 6nm process - a significant advancement from previous nodes
- Chiplet-based design continues refined Tensor AI Accelerator architecture
- HBM3 integration despite packaging limitations and supply chain constraints
Industry Expert Analysis and Concerns
Technical experts have raised important considerations about the 920C specifications:
Performance Comparison Validity:
- CloudMatrix 384 vs GB200 NVL72 comparisons questioned due to different cluster sizes
- Power consumption concerns: 559kW vs 132kW represents significant efficiency gap
- CANN vs CUDA ecosystem maturity remains unaddressed challenge
Supply Chain Questions:
- HBM3 sourcing: Dependency on Samsung/SK Hynix/Micron creates potential bottlenecks
- GB200 availability for comparative benchmarks raises authenticity questions
- Yield and ramp-up speed reportedly faster than GB200, which experts find "incredible"
Strategic Implications:
- Low yields (20-40%) don't make 920C financially unviable due to cost structure
- Local demand likely to absorb production, limiting international availability
- Unit price and power consumption remain key competitive factors per industry analysis
Addressing Industry Controversies
Debunking the Cost Controversy
Recent market discussions have questioned DeepSeek's pricing model, with some claiming their costs are artificially low. However, industry analysis reveals:
Key Competitive Advantages:
- China's "Artificial Sun" nuclear fusion breakthroughs demonstrate advanced infrastructure capabilities
- Multi-vendor GPU Strategy: Utilizing chips from Huawei, Biren, and Moore Threads creates competitive pricing
- Optimized Software Stack: Custom CUNN kernels and DeepSeek's engineering excellence enable superior efficiency
Real-World Evidence:
- DeepSeek R1 distilled models successfully run on Huawei Cloud equipped with native Chinese chips
- The partnership between Huawei and DeepSeek was established "a long time ago," indicating deep technical integration
- Training on Nvidia H800 while inferencing on Huawei 910C creates hybrid cost optimization
Why Export Controls Backfire
The strategy of tightening export controls on advanced chips may inadvertently accelerate Chinese AI development:
Unintended Consequences:
- Forces rapid development of domestic alternatives like Huawei Ascend series
- Pushes China to create independent CUDA ecosystems through CUNN
- Eliminates dependency on US technology, creating long-term competitive disadvantage
Innovation Acceleration:
- US export restrictions create urgency for Chinese chip development
- Open-source AI models reduce barriers to entry for global developers
- Competitive pricing forces innovation across the entire industry
Future CloudMatrix Evolution and Industry Impact
Planned Architecture Enhancements
Next-Generation CloudMatrix Features:
- Unified VPC/RDMA planes for simplified network architecture
- Larger-scale supernodes beyond 384 NPUs for massive model support
- Physical CPU disaggregation and pooling for enhanced flexibility
- Component-level disaggregation for fine-grained resource allocation
Serving System Improvements:
- Hybrid and adaptive deployment strategies
- Enhanced distributed caching with elastic memory services
- Advanced parallelism strategies including improved TP/DP/EP combinations
Strategic Industry Implications
The CloudMatrix384 achievements demonstrate that Chinese AI infrastructure is not just competitive but potentially superior in specific metrics:
Performance Leadership:
- 4.45 tokens/s/TFLOPS prefill efficiency exceeds published Nvidia H100 results
- Large-scale expert parallelism (EP320) enables unprecedented model scaling
- Sub-15ms TPOT latency achievements rival best-in-class systems
Ecosystem Maturity:
- Production-grade deployment with comprehensive software stack
- Open-source integration supporting multiple ML frameworks
- Real-world validation through DeepSeek's commercial deployment
Industry Reality Check: While power consumption (559kW vs 132kW) and ecosystem maturity (CANN vs CUDA) present ongoing challenges, the CloudMatrix384 results demonstrate clear technical capability. Expert analysis confirms that with 6,688 tokens/s per NPU prefill performance and INT8 quantization maintaining accuracy parity, Chinese AI chips are becoming not just financially viable but technically competitive.
Conclusion: The Technical Revolution in AI Infrastructure
The comprehensive analysis of CloudMatrix384 and its detailed component architecture reveals a fundamental transformation in AI infrastructure that extends far beyond simple hardware comparisons. The DeepSeek-Huawei partnership represents a sophisticated technical achievement that challenges conventional assumptions about AI hardware leadership.
Architectural Innovation Leadership:
The CloudMatrix384 system demonstrates several breakthrough capabilities that exceed conventional cluster designs:
- Peer-to-peer architecture eliminating hierarchical bottlenecks that limit traditional AI clusters
- Unified Bus (UB) Network enabling direct all-to-all communication with unprecedented bandwidth efficiency
- Resource disaggregation allowing independent scaling of prefill, decode, and caching operations
- Expert Parallelism (EP320) achieving the largest-scale expert parallelism deployment in production
Production-Grade Performance Validation:
The technical deep-dive into individual components reveals mature engineering capabilities:
- Ascend 910 NPU: Specialized AI cores with AIV-Direct communication bypassing traditional network stacks
- CANN Framework: Comprehensive software stack with MLAProlog, Fused Attention, and optimized quantization kernels
- SGLang Integration: 4.45 tokens/s/TFLOPS prefill efficiency exceeding published Nvidia H100 results
- INT8 Quantization: Maintaining model accuracy comparable to DeepSeek-R1 API across 16 distinct benchmarks
Strategic Technical Implications:
The CloudMatrix384 architecture demonstrates that Chinese AI infrastructure development has achieved:
- Performance Leadership: CloudMatrix-Infer delivers 6,688 tokens/s per NPU prefill throughput with <15ms TPOT latency achievements
- Ecosystem Maturity: Production deployment with comprehensive CANN software stack supporting PyTorch, TensorFlow, and ONNX
- Architectural Innovation: Peer-to-peer design enabling uniform memory access across 384 NPUs with dynamic resource pooling
- Cost Efficiency: Hybrid deployment model leveraging both ecosystems' strengths for optimal performance-cost balance
The New AI Hardware Paradigm:
As DeepSeek R1 continues topping global app store charts and Huawei scales from 910C production to 920C mass production in H2 2025, the evidence from CloudMatrix384 demonstrates that the AI hardware landscape has irreversibly changed. The technical specifications, performance benchmarks, and production deployment details prove that the question is no longer whether Chinese AI can compete—it's how quickly the rest of the world will adapt to this new paradigm where performance leadership, cost efficiency, and architectural innovation are no longer mutually exclusive.
The CloudMatrix384 case study establishes that with 671B parameter models running efficiently on Chinese hardware, EP320 expert parallelism achieving production-scale deployment, and peer-to-peer architectures enabling unprecedented scalability, the future of AI infrastructure will be defined not by single-vendor dominance but by technical excellence, architectural innovation, and cost-effective deployment strategies that democratize access to state-of-the-art AI capabilities.
Sources
- Serving Large Language Models on Huawei CloudMatrix384
- Huawei Cloud official materials on CloudMatrix and Ascend architecture (whitepapers and docs)
- Public benchmarks and statements referenced by DeepSeek engineering updates (#OpenSourceWeek)
- Industry reporting on Ascend 910C/920C yield, capacity, and specs (FT, CSIS, other)
FAQ
Is Huawei Ascend 910C faster than Nvidia H100 for LLMs?
It depends on workload and optimizations. Reported prefill/decode efficiency on CloudMatrix384 is competitive for MoE/MLA serving, but Nvidia still leads on power efficiency and ecosystem maturity.
Can I migrate PyTorch CUDA code to CANN/CUNN easily?
Basic models can migrate with limited changes, but performance-critical kernels may require work. Assess operator coverage and library support first.
When will Ascend 920C be available?
Reports indicate mass production targeting H2 2025. Availability and pricing are subject to change.
Are the token price figures guaranteed?
No. They are reported promotional prices and can vary by provider, region, and traffic profile. Validate against your provider.
What are the main trade‑offs vs Nvidia GB200?
Pros: competitive throughput, strong MoE scaling, potential cost per token. Cons: higher power, ecosystem maturity, supply chain constraints.
External Resources
What You Can Do on This Page
In-Depth Analysis of CloudMatrix384 with Ascend 910/920: How DeepSeek Cuts AI Costs by 90% vs Nvidia H100
This article provides a thorough analysis of CloudMatrix384 with Ascend 910/920: How DeepSeek Cuts AI Costs by 90% vs Nvidia H100, covering the implications for GPU cloud computing, AI infrastructure, and the broader technology landscape. We examine the key developments, compare options, and provide actionable insights for researchers, engineers, and decision-makers evaluating their GPU strategy.
Understand How This Development Affects Your GPU Decisions
Whether you are planning GPU cloud deployments, evaluating hardware options, or optimizing costs, understanding industry developments is crucial. This analysis provides context on how the covered topics affect GPU rental pricing, availability, and the competitive landscape across cloud providers.